머신러닝(Machine learning=기계 학습)이 몇년 전부터 알려지기 시작했습니다. 심지어 개발자가 아닌 일반 소비자들도 머신러닝에 대해 알 정도죠. 우리가 아마존에서 어떤 물건을 장바구니에 담았을 때 관련 상품을 추천하는 것 등이 머신러닝의 가장 보편적인 예입니다. 머신러닝의 기본 개념은 데이터를 기반으로 스스로 학습하고 자신만의 룰을 만드는 컴퓨터 프로그램의 산물입니다.
머신러닝 애플리케이션 개발은 일반적인 애플리케이션 개발과는 다릅니다. 머신러닝 개발자는 코딩이나 특정 문제를 해결하는 대신 알고리즘을 짜고 데이터를 기반으로 고유한 로직을 만듭니다. 아마존의 예와 같이 소비자의 행동과 판매에 관한 데이터는 사람들이 좋아하거나 관심 있어 하는 제품이 무엇인지 파악하는 데 사용되곤 합니다. 이것은 단순히 사용자의 카트에 담긴 물건과 마케터나 판매 담당자가 추천하는 제품과의 1:1 관계를 찾는 것이 아닙니다. 모든 방문자와 판매된 모든 제품 등으로부터 발생되는 모든 데이터를 계산해 예측하고, 다음 행동과 결정에 도움을 주는 것이죠. 새로운 제품 과 새로운 데이터는 항상 유입되고, 그에 따른 추천 결과는 지속적으로 변경되고 개선됩니다.
왜 머신러닝에 이토록 관심을 가질까요? 최근 사물인터넷(IoT)의 부상으로 연결되는 장비가 증가하면서, 또 많은 양의 데이터에 쉽게 접근할 수 있게 되면서 데이터를 관리하고 데이터가 의미하는 것이 무엇인지 이해하고자 하는 요구가 증가했습니다.
또한 다양한 산업에서 머신러닝을 활용하기 시작했습니다. 그 덕분에 개발자들은 머신러닝을 어떻게 활용할 것인지 그리고 이 기술이 제품에 어떤 가치를 가져다 줄 것인지 학습하는 아주 좋은 기회를 가질 수 있게 됐죠.
머신 러닝 알고리즘의 종류
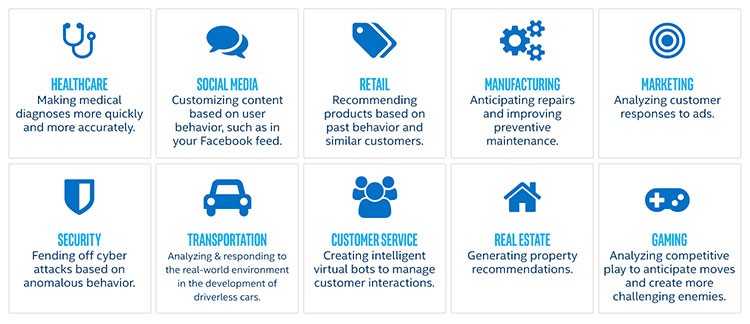
데이터를 다루는 산업은 데이터가 의미하는 바를 이해함으로써 큰 이득을 볼 수 있습니다. 가령 제조 공장은 수리 시점을 예측할 수 있고, 무인 자동차 같은 것도 머신러닝의 결과라고 할 수 있죠. 다음은 머신러닝을 사용하는 산업군들입니다.
새로운 트렌드로 떠오르는 '챗봇(Chatbot)'
올해 페이스북 메신저가 챗봇을 발표했는데요. 이는 회사와 컨슈머로부터 엔게이지를 끌어낼 수 있는 가능성을 만듭니다. 고객이 페이스북 페이지로 메시지를 직접 보낼 경우 인공 지능(AI)이 고객과의 상호작용을 통해 의사 결정이나 제품 학습에 도움을 줍니다. 이러한 모든 상호작용은 챗봇의 기능을 더욱 향상시킵니다. 특정 트랜잭션은 메신저 내에서 어떤 특정 기능도 수행할 수 있는데요. 가령 자동차 아이콘을 클릭하면 우버(Uber)에 콜을 보낼 수도 있습니다.
챗봇은 텍스트를 보내는 단순 기능에서 이미지나 콜-투-엑션(call-to-action) 버튼에 이르는 자동화된 고객 서비스, e커머스 비서, 심지어 콘텐츠 서비스 등도 가능합니다. 정확도는 지속적으로 업그레이드되고 있으며, 이는 자동화된 컨시어지(concierge)와 비슷하죠. 고객이 더 쉽고 빠르게 자신이 원하는 정보와 서비스를 얻을 수 있게 된 셈입니다. 이 부분은 가장 큰 트렌드이며 '대화형 커머스'로 불리기도 합니다. 모바일 메신저 앱과 인공지능의 힘을 키우는 기회인 것이죠. 미래 쇼핑은 채팅 창 안에서 이뤄질 것입니다.
머신러닝 첫걸음
출처: http://m.blog.naver.com/intelbiz/220859379249
'Insights & Trends > Technological/Scientific' 카테고리의 다른 글
| [스크랩/자동차/자율주행] SKT.KT.LGU+ 이통3사, ‘자율주행차’ 사업 경쟁 가열 (0) | 2017.03.21 |
|---|---|
| [스크랩/인공지능] 쉽게 풀어쓴 딥러닝(Deep Learning)의 거의 모든 것 (0) | 2016.09.22 |
| [스크랩/인공지능] <웹진 176호 : 공학 트렌드> 인공지능 - 머신 러닝 편 (0) | 2016.05.17 |
| [스크랩/미래/전망] `모바일퍼스트` 생존 화두? 누구나 즐겨찾는 플랫폼 ! (0) | 2016.04.22 |
| [스크랩/통신] 사물인터넷 전국망, SKT `로라` vs KT `LTE-M` 격돌 (0) | 2016.03.17 |



